Despite the global proliferation of language models, there is a pressing need to expand evaluation across a broader array of languages. However, due to the associated costs and the risk of evaluation sets becoming unwieldy in size, we have decided to concentrate our efforts on two languages: English and Chinese. The selection of these two languages is primarily based on two considerations: (1) As explained in [1], English and Chinese are the languages most frequently used in the fields of artificial intelligence and natural language processing; (2) As we have statistically analyzed in Section 8 of our report, the training corpora for current models are also predominantly composed of these two languages.
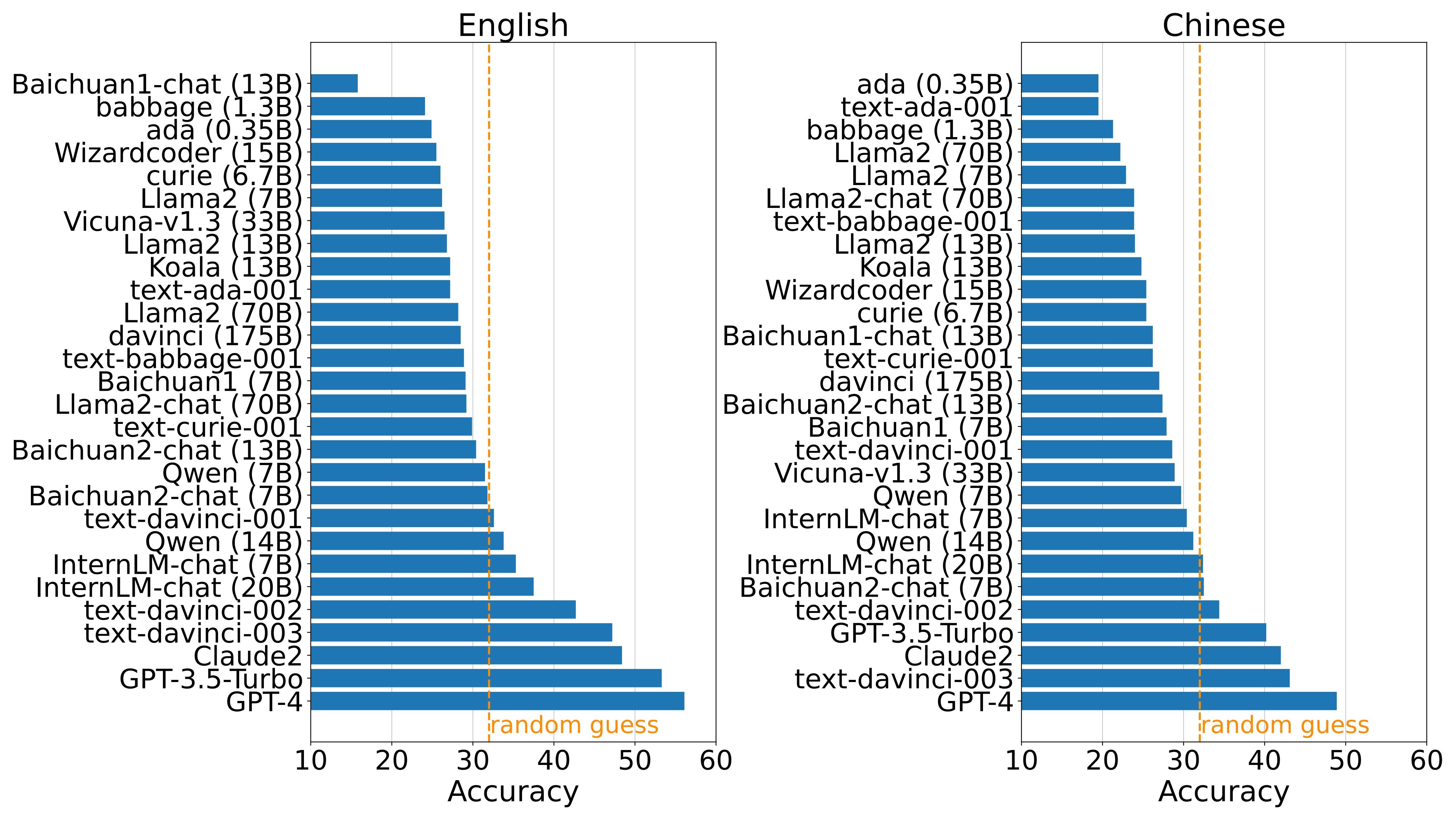
As shown in the following figures, it is evident that models generally perform better in English causal tasks. This finding aligns with our initial hypothesis, given that the training corpus for most current language models predominantly consists of English data. Specifically, the number of models performing better than random guesses in English causal tasks is nine, compared to seven in Chinese causal tasks. In English causal tasks, both GPT-4 and GPT-3.5-Turbo, ranked first and second respectively, achieve an average accuracy exceeding 50%.
Conversely, in Chinese causal tasks, even GPT-4’s performance does not surpass the 50% threshold. Despite these variations in accuracy across languages, the top five models remain consistent, albeit with minor differences in their specific rankings. These models are GPT-4, GPT-3.5-Turbo, text-davinci-003, text-davinci-002 from OpenAI, and Claude2 from Anthropic.
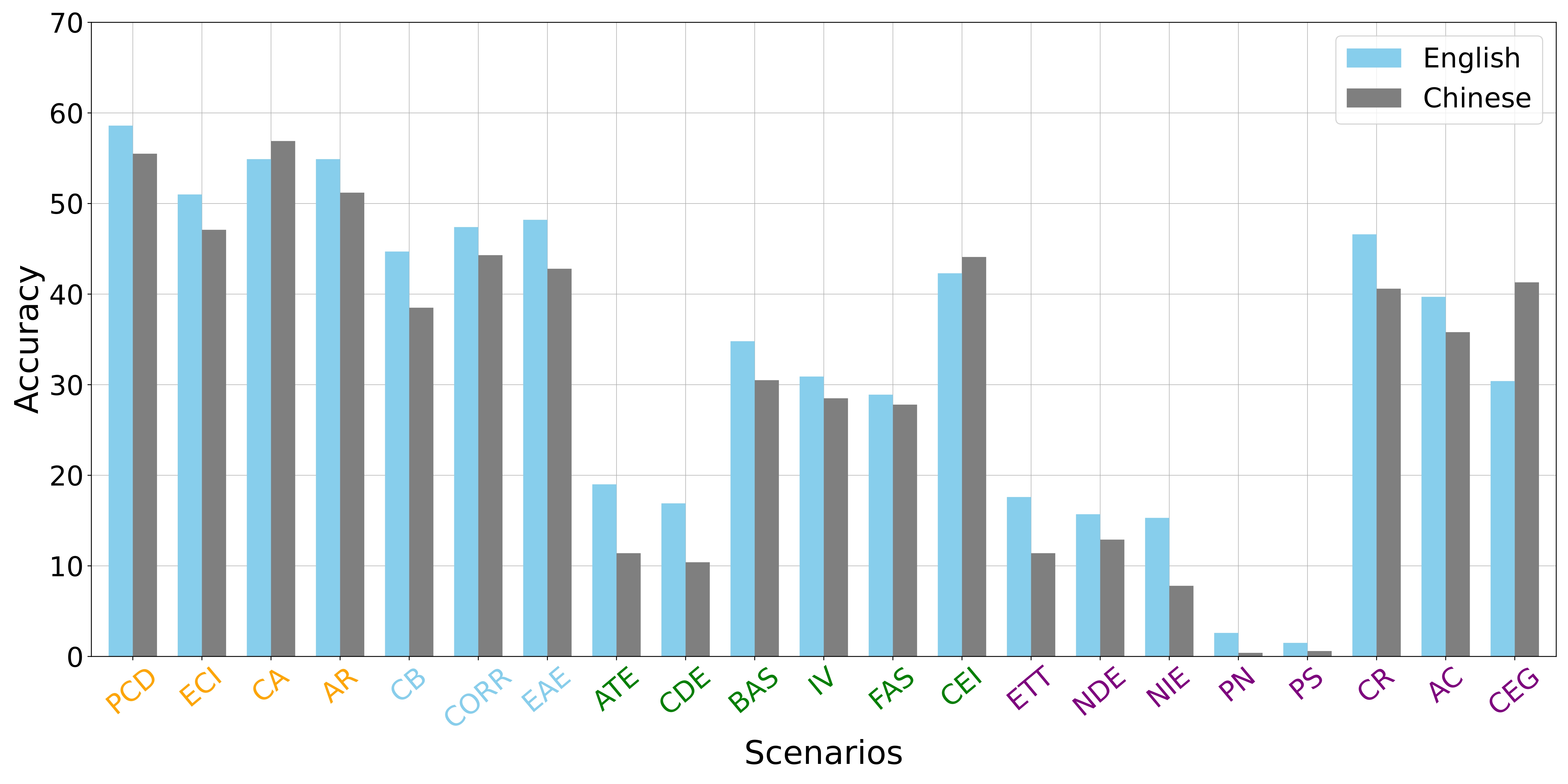
We also explore the relationship between accuracy and multilingual in the above figure. For each language type, we calculate the average accuracy of all models in that category for the corresponding scenario.
[1] Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y., Narayanan, D., Wu, Y., Kumar, A., et al. Holistic evaluation of language models. arXiv preprint arXiv:2211.09110, 2022.