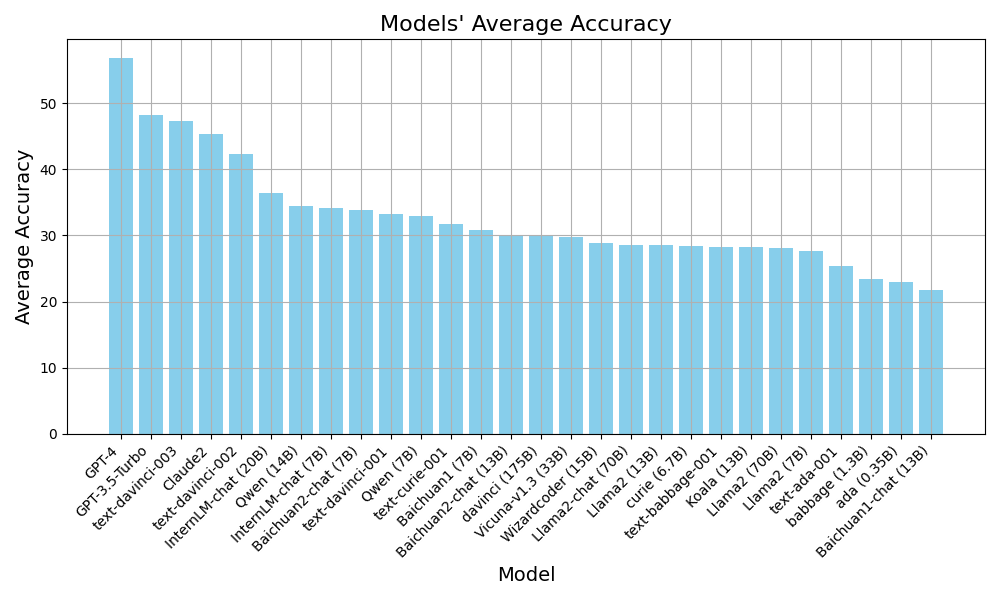
Here we evaluate the overall performance on all scenarios. Taking a comprehensive look, among the models ranked in the top 10 on CaLM, limited and open-source models make up half. However, all models in the top 5 are limited-source, with text-davinci-002, ranked fifth, leading the sixth-placed InternLM-chat (20B) by almost 6%. This suggests that for causal reasoning scenarios, there remains a noticeable difference between open and limited-source models. In every scenario and for all prompts, GPT-4 secures the first position with a significant lead of nearly 8% over GPT-3.5-Turbo, which is ranked second.
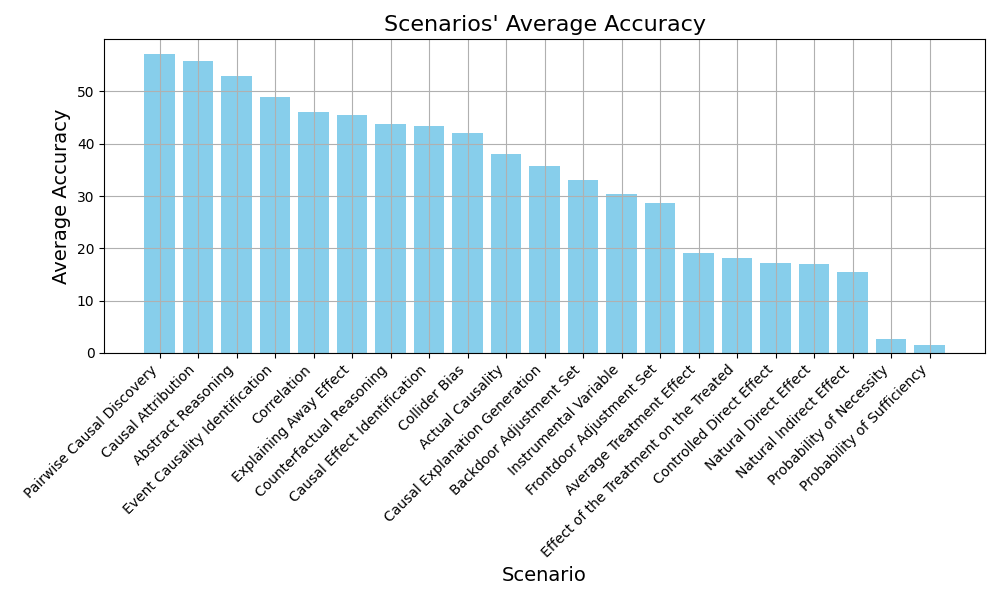
We show the scenario analysis in the following. It turns out that models are more good at scenarios within lower rungs of the causal ladder.